Hi, author here. My version definitely shouldn't be faster unless something very weird is going on with the runtime (though I think with the benefit of hindsight some further optimisation of it is possible). I have never seen a good use for this, aside from as a proof that it is possible, but I can imagine it coming up if, say, you wanted to write an exploit for an esoteric programming language runtime.
If you still maintain this code and want to optimise it, I don't think you should need a full powers-of-two table, just having log(n) powers of two should do in a pattern like:
if (v > 2**1024) { v *= 2**-1024; e += 1024; }
if (v > 2**512) { v *= 2**-512; e += 512; }
...
That's a straightforward memory saving and also leaves v normalised, so gives you your fraction bits with a single multiplication or division. This is a little less simple than I'm making it look, because in reality you end up moving v to near the subnormal range, or having to use a different code path if v < 1 vs if v >= 2 or something. But otherwise, yeah, the code looks good.
Thanks for the feedback, and congrats on your achievement.
We do still maintain this code, although it is deprecated now.
Even with the unrolled tests, we would still keep the table for the decoding operation, I believe. But it's true that it would at the same time provide the normalized value. That could be beneficial.
Author here - I believe this 2020 post resurfaced as known-bits optimisation was recently added to PyPy (Python implementation using a JIT compiler), which this thread discusses:
It includes discussion of where this kind of optimisation helps (not most "normal" Python code, but some code like emulators with lots of bitwise operations is ~30% faster), links to LLVM and Linux kernel implementations, and some related blog posts and papers. (I believe the Linux eBPF people came up with all of the ideas here before I did, though I wasn't aware of it at the time - it's easy to forget the Linux kernel has an optimising compiler in it.)
I'm not sure if that's what you mean by context - happy to answer questions.
There’s an example in the linked thread. Suppose you write some code like
if (a+b) % 2 == 0:
…
And the compiler is able to figure out that a and b are even (that is they both have 0 in the lsb), or if it figures out that a = b, this kind of known-bits tracking allows it to get rid of the branch. The code in the OP can be used to make tracking known-bits fast enough to be practical
To try to make it more "concrete", compilers tend to end up processing an absurd mess of code, that does things that superficially look silly, due to extensive inlining.
The code above is entirely plausible for C code checking the alignment of a total size, where "a" and "b" are the sizes of two parts, both calculated by a multiplication that ensures their evenness.
Another realistic examples are flags-fields, where each bit represents a boolean. For example, the compiler should be able to optimise:
flags |= 0x100;
if (!(flags & 0x100)) { ... }
Addition might factor in either as a substitution for bitwise-OR or bitwise-XOR where the author has prior knowledge that the two are equivalent (and assumes it will lead to better code generation), as part of SWAR (simd-within-a-word) code, or in cases where integer fields are packed alongside flags (e.g. a refcount and a couple of flags, or a string-length and some flags).
If this seems rare and unusual, that's cool – in general it is. But these strategies are very heavily used in performance-critical code, where using multiple variables would cause a measurable slowdown, so it makes sense that compilers care about optimising this kind of thing.
I hope it's useful, though I think most people care about the "Advanced SIMD" (Neon) instructions, which I'd also like to do. I started with SVE because I wasn't already familiar with it, so it was a more interesting project.
(For anyone unfamiliar, SVE is supported only on extremely recent ARM CPUs, and Apple CPUs do not yet support it, whereas AdvSIMD is available on all ARMv8-A CPUs.)
Heh, I'd have called it the Arm SIMD Instruction List, but Arm have been aggressively enforcing the Arm trademark [1], so I settled for A64 (the official name for the instruction set [2]).
On x86-64 you are free to manipulate the 16 MSB bits of an address however you like. The only micro-architectural restriction is that the 16 msb bits are all either 0 or 1. Otherwise you get a GPF. One way to tag pointers is mask off 15 higher bits and do zero or sign extend based on 16msb bit prior to memory dereference with MOVZX or MOVSX instruction. No need for shifts and other magic. I think in this scenario the unsigned numbers can retain their plain arithmetic semantics after masking off of a single MSB bit without a need for shifts etc. alternatively when loading/operating on arrays its type can be encoded in the pointer to the array by the above scheme while data can be stored in POD format again with no extra shift etc.
It is a trade off, but a lot of processors have free offsets from loads, so pointer chasing is almost always free.
On ARM, "ldr x0, [x1]" just becomes "ldur x0, [x1, #-1]" - same size, same performance (at least on the Apple M1). If you have an array in a structure "add x0, x1, #16 ; ldr x0, [x0, x2, lsl #3]" becomes "add x0, x1, #15 ; ldr x0, [x0, x2, lsl #3]".
The only place I can think of penalties are pointers directly to arrays: "ldr x0, [x0, x1, lsl #3]" becomes "sub x0, x0, #1 ; ldr x0, [x0, x1, lsl #3]". Or loads from large offsets - ldur can only reach 256 bytes, whereas the aligned ldr can reach 32760 bytes. In either case the penalty is only one SUB operation.
By the way, at least for pointer arithmetic, this makes a lot of sense: adding two valid addresses never makes sense, so ptr+i always results in a valid pointer (assuming i is a multiple of sizeof(ptr)).
With pointers having lowest bit set, you'd check if the LSB is set and then do for example (uint32_t *)((char *)p - 1) + 2 which the compiler would optimize to register + 7 instead of register + 8, i.e. the penalty would be exactly zero for any other offsets beside 0.
That's by design. Implicit masking used to be the norm in older architectures, but programs would store data there with impunity and it would make it harder to extend the address space, so AMD64 requires most significant bits of an address to be either all 1 or all 0.
Yeah, but I'm talking about lower bits, not the upper bits.
Off-tangent: virtual pointers on AMD64 are effectively signed numbers and yet most low-level intro-level programming books keep saying that "pointers are unsigned ints because it doesn't make sense for pointers to be negative, bla-bla". Hell, I believe xv6 book has this passage and the passage about pointers' upper-bits on AMD64 being either all 1 or 0 on the same page!
Ah, ok, but now you can't do subword aligned read/writes. That was a costly mistake that Alpha originally made and most architectures have avoided since.
That depends on ISA's details, honestly. For example, Knuth's MMIX has 64-bit words and has separate intructions to load/store 8-, 16-, 32-, or 64-bit wide chunks of data to/from memory — which are forced to be naturally aligned because 0, 1, 2, or 3 lower bits of the address are masked, depending on the data access's width. So there you go, you have aligned access for all "natural" subword sizes.
Don't most contemporary high performance processors support unaligned memory operations? An eight byte load with non-zero vaddr[2:0] from an all zero one
Browsers use multiple processes for security and reliability, not as an alternative to multi-threading. They extensively use multi-threading for performance (as does a lot of other modern software).
The reason is that I'm trying to keep my messages effective. If I complain against everything at the same time, I risk being ignored.
I don't like the closed nature of GitHub neither. I hope the free software world move away at some point.
The open source world can't seem to avoid locking itself in those closed tools, I would really like if we stopped doing this.
I chose Discord because I see it as a bigger issue than GitHub, with which one can interact with standard tools like emails and git, and basic stuff work without JS. So one can both refuse to run non-free code and interact with GitHub. Still not ideal and concerning.
Try to go back to the early 2000s and tell someone that the open source world is going to trust MS to host all their stuff. You would probably have difficulties to be taken seriously.
(Although it is to be noted that back then many people used SourceForge which was also proprietary)
Absolutely fair to call out both on similar grounds on openness and privacy being proprietary (publicly-traded megacorp vs. VC funded). One difference would be at least GitHub results can be found with a search engine and without authentication (though you cannot use the search for “Code” without an account).
How many times have you been hacked by a side-channel exploit? (Or people you know? Or any publicly documented case?) Are you going to use a computer that runs at 1/10th the speed to mitigate that risk going forwards?
Keep in mind that a ton of non-side-channel exploits are caught in the wild every year, so your slow new computer isn't really secure, it's just not vulnerable to these specific attacks.
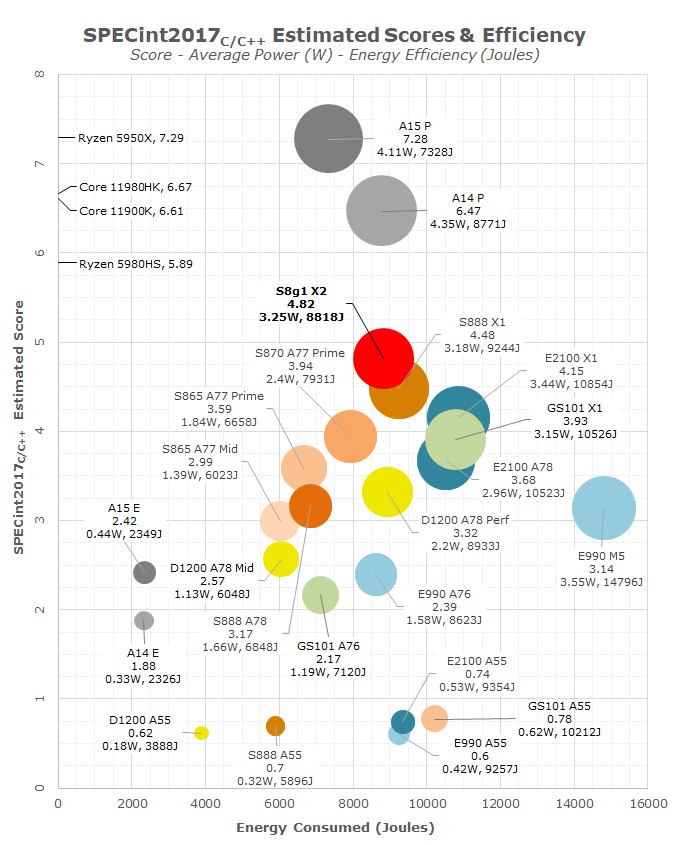
(For 1/10th: the Cortex-A55 in the following chart is the only "in-order" CPU: https://images.anandtech.com/doci/17102/SPECint2017_575px.pn... - though arguably even it isn't completely non-speculative, and it definitely has branch-prediction, but it's at least a reasonable ballpark.)
The problem is that security is only important when you're running your valuable IP code and extremely private data on someone else's computer, right next to arbitrary code written by a third party.
No, that's nothing like my day-to-day work in a text editor and compiler or CAD app on my personal box, where choosing performance over security is obvious. But it basically describes the hyper-competitive modern cloud computing ecosystem exactly.
Unfortunately, due to consumer irrationality and imperfect information, economics seems to indicate that the best way to get money out of the value that can be added through software is to sell subscriptions to online services, not shrink-wrapped DVDs. Now that this has been discovered, I think we're unlikely to get a world where we all have insecure, high-performance local machines that don't depend on cloud services.
I've never personally been hacked by a side-channel exploit. A customer I work with recently got hacked by ransomware, which was scary, they've spent the last month wiping everything and restoring ~95% of their data from backups, but I feel safe assuming I'm just not interesting enough to be at risk of to high-effort spear-phishing hardware side channel attacks.
> The problem is that security is only important when you're running your valuable IP code and extremely private data on someone else's computer, right next to arbitrary code written by a third party.
I mostly agree in principle but disagree with your introduction. Unless you don’t use a web browser.
Your browser is an untrusted computing environment that is constantly downloading and running 3rd party code in sandboxed environments.
A modern browser looks a lot like an edge node running on-demand short-lived programs from 3rd parties.
Not sure you read that chart right. It's slower because it's much lower power.
Out of order execution gives on the order of 2x speed improvement not 10x. I would imagine branch prediction gives a much bigger benefit but nobody is going to make a performance sensitive processor without branch prediction (whereas in-order is still common).
{kind=link}
If you still maintain this code and want to optimise it, I don't think you should need a full powers-of-two table, just having log(n) powers of two should do in a pattern like:
That's a straightforward memory saving and also leaves v normalised, so gives you your fraction bits with a single multiplication or division. This is a little less simple than I'm making it look, because in reality you end up moving v to near the subnormal range, or having to use a different code path if v < 1 vs if v >= 2 or something. But otherwise, yeah, the code looks good.reply