I remember being insanely impressed by GPT-2 in 2019. It's remarkable how something just a few years behind the state-of-the-art completely fails to impress anymore.
Reading this, all the changes in modern models like gpt-3 seem like pretty incremental improvements - better structured training data (and a lot more of it), using tokens instead of characters, etc.
They are. Nobody in the AI research community expected that scaling up models several orders of magnitude would make them that good. Even the original selling point of the Transformer paper was "can be much bigger and faster than RNNs, even if not as good" - Of course everyone was wrong and it's all about the data and scale.
Btw, tokens are nothing new in modern models. They've been used since 2015/2016 [0]
Which goes to show you one of the best strategies in ML isn’t necessarily thinking about learning theory, it’s thinking about what our fastest computers are most capable of doing.
But this does run out of steam (or rather…data) eventually. The largest LLM was ibm’s tangora model back in the 1980s. 8 trillion params.
We’ll go through the cycle again with a new paradigm.
There was a similar argument for not improving the efficiency of software in general - why bother to improve the design if upgrading the underlying hardware can double performance without changing the software?
It's not entirely invalid, but it does encourage a rather blasé attitude towards actually understanding the problem that you're dealing with.
"It just goes to show the best strategy in assembling wood together isn't learning to use a screw driver, its about pounding it in with the hardest and most capable hammer."
I'll acknowledge Large Hammer Models have done surprisingly well, but true General Artificial Fastening is obviously not just Hammer models scaled up. There's things a screw driver can do which a hammer is hopeless on. Such as taking apart your eye glasses (and more importantly, putting them back together). This isn't something that is going to be solved once the tradesmen have a bit more training. Its fundamental to the way hammers work. We can only do so much by hammering in all our screws.
> The largest LLM was ibm’s tangora model back in the 1980s. 8 trillion params.
As far as I can tell, this comes from a typo in a 1992 paper? https://aclanthology.org/J92-4003.pdf Does it mean the space of possible inputs is 8 trillion?
It's an n-gram model so it can easily have as many parameters as you want to store. Skimming it, I think the '8 trillion parameters' here means '8 trillion trainable n-gram parameters but it's very sparse and most of them are simply defined by omission to be a small constant like epsilon due to not being represented in the training data at all and so suffering from the 0-count problem'. (Old problem - even Turing and Good spent a lot of time discussing how to handle 0s in contingency tables because that happens a lot in cryptography!)
I think the 8 trillion parameters is accurate- Tangora is an N-gram model with a vocab size of 20,000 words and N = 3.
Parameters for an N-gram model = V^(N-1) * (V-1)
Plugging in V=20,000 words and N = 3 for Tangora, you'd get 7.9996E12.
Most of the parameters are likely zero or close to it because many 3-grams are possible but not likely to occur. (However the aggregate probability of all 3-grams is substantial and thus they have to be included.)
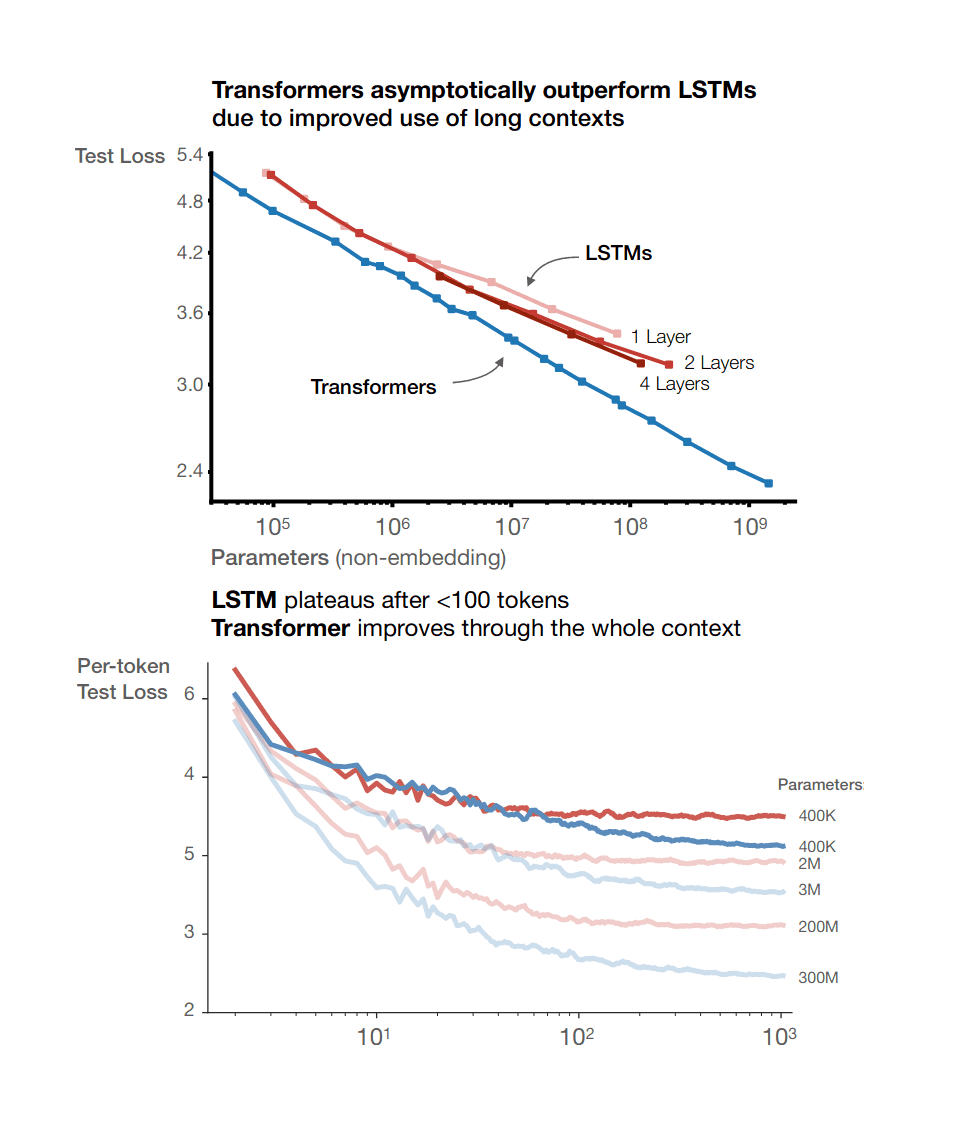
That's because the big change was moving from LSTM RNNs to Transformers. If you had tried to train a scaled-up RNN on GPT-3-level compute and data, it would have been a much better RNN, yes... and terrible compared to GPT-3, because the RNN scaling law is much worse and they are unable to make good use of context. See Kaplan et al 2020, key graph: https://gwern.net/doc/ai/nn/transformer/gpt/2020-kaplan-figu... (I'm not going to try to calculate it, but by 'terrible' I mean that the bent scaling law would give you, like, GPT-2 performance for GPT-3-level investment. Suffice it to say that the DL conversations would be a trifle different today if that had been what happened.)
All the other stuff has been largely minor polishes. For example, using tokens instead of characters? Nah. ByT5 works fine, as do very large context window approaches like Jukebox. Large BPE vocabs may be somewhat more efficient but the value is nothing like RNN->Transformer. A lot more training data? Doesn't matter if your model scaling law is bent because the model can't make use of more data meaningfully - it's not like it's overfitting to smaller amounts of data either, it's just underfitting everything. Structure? Irrelevant, the point of web scrapes is bulk and diversity. etc
RWKV is interesting but hasn't shown Transformer-beating improvement yet, and its key is that it's training in a quasi-Transformer manner to begin with, which is why it gets the better scaling law that makes it feasible, and so demonstrates my point. (RWKV is more like a Transformer which is easily converted into a RNN for sampling, which is an equivalence we've known for a long time.)
It's beaten by only two weights available models, it beats LLama 13B and Dolly. What do you mean it's training in a quasi-Transformer manner? Do you mean the language pretraining? That's been done before Transformers.
RWKV doesn't have the quadratic attention of Transformers, so I'd say it's pretty different.
Transformers don't all use quadratic attention; there's a whole zoo of alternate attentions. And even the RWKV author refers to it as 'transformer mode'.
Another one that is starting to get on my nerves (though not really in the same category as the above) is "first world problem". Person A states they have some kind of problem and person B says "tisk, tisk, first world problems" in order to attenuate whatever problem person A has. If person B is currently living in the 3rd world under 3rd world conditions, fine, otherwise stop cheaply leveraging the poor in order to win arguments.
{kind=link}