I've recently been using http://halide-lang.org/, a language designed to separate the specification of an algorithm from the order of the computations and the layout of the data in memory. It allows you to first get an algorithm working and then quickly try a huge number of permutations of the options for data layout, parallelism, and vectorization. You can get incredible speedups vs. a naive series of C for loops.
This is where I feel functional languages will have a huge advantage in coming years. As side effects are reified and put in the compiler's control, they can be modified and optimized automatically.
While TFA is interesting, and a pretty good overview of designing programs with the cache in mind, it just shows me how far we have to go in language design. I don't want to manually make all of these modifications, let alone carefully profile each permutation of all the possible choices. We have fast, dumb computers, let them do that work.
Sure, this is the myth of the sufficiently smart compiler [1]. The problem is that such compilers generate fast code until you hit an edge case and then suddenly they're slow. Today, JavaScript is the canonical example; you never know how fast code will run without benchmarking, and it changes with each browser release. Or take SQL for another extreme example, where performance depends on the index you hit and the query plan the database comes up with.
To counter this, people invent things like the asm.js specification, which tells you exactly what you need to do to make JavaScript fast, and then we're programming in assembly again. (Or perhaps C++.)
So there is still plenty of room for languages that aim for predictable performance. I believe this is where Go and Rust are headed.
The problem is not so bad if the compilers explain themselves. I run g++ or gcc with --ftree-vectorize-verbose=3. So even if gcc wasnt able to vectorize a loop I get to see which one it failed on and why. This is very valuable and you can often tweak the code to fix the problem. It saves me the trouble of writing intrinsics by hand. A "sufficiently smart programmer" could do better, but they are rare too.
I would also like better feedback from compilers, and not just in the form of messages. It seems that throughout most of history compilers have been traditionally "one-way", i.e. you give them source and they produce a binary. To assist with code generation, what they should really be doing is some sort of "decompiling" of their optimiser's output back into e.g. C, maybe even with comments, so you can get an idea of what high-level optimisations it performed and where.
Just for the off hand chance that you are unaware of this, the option -fdump-tree-optimized on GCC and the other -fdump-tree.* options will do some of what you are asking for.
GCC isnt hipster hot nowadays but it has quite a few nice things. For C++ templates I still prefer G++ error messages over Clang++'s. I find the former a lot more informative, but without Clang breathing down their neck I doubt if they would have improved their error messages.
Not entirely. In Rust, the runtime representation of enums (tagged unions) is left deliberately unspecified in order to allow for arbitrary optimizations depending on shape.
For example, The Option type in Rust (a.k.a. the Maybe type in Haskell) is a tagged union defined like this: [1]
enum Option<T> {
None,
Some(T)
}
Now say I use this like so:
let foo = Some(6);
The runtime represenation of `foo` will be as follows:
struct FooRepresentation {
discriminator: u8,
value: int
}
...where `discriminator` is the field that determines whether the value is `None` or `Some`, and in the latter case `value` will contain the associated data.
But let's say I declare foo a bit differently, using a pointer to a value rather than a raw value:
let foo = Some(~6); // the tilde denotes a unique pointer
Now the runtime representation of `foo` is only a single pointer, and in order to determine if `foo` is `None` it just checks to see if the pointer is null. Rust is smart enough to perform this optimization on any tagged union with two variants where only one of the variants has associated data, and the type of that variant is a pointer.
On the flipside, if you want to guarantee a specific data layout then you can use a struct, which have the same layout rules as structs in C.
Not go or rust, but I'm curious, in ocaml or haskell, I imagine it is not easy to change data representation without refactorings, because of the widespread pattern matching? e.g. in ocaml: let (x,y) = point;;
That's one of the reasons why record types are recommended instead of tuples. They don't cost anything at runtime but make it harder to shoot yourself in the foot.
> and then we're programming in assembly again. (Or perhaps C++.)
Is that so bad? The reason we're in JS in the first place in those environments isn't because it's the best language for the job, it's because it's the only language that can be used in that environment.
Ah yes, the functionalist dream: "Given a sufficiently-advanced compiler, executing arbitrary code with ideal performance is trivial". Sadly, such a compiler has been "about ten years away" since the Lisp Machine days...
That's what I like about Halide: it doesn't rely on a sufficiently-advanced compiler. The optimizations are specified explicitly, with full programmer control. The difference is in Halide the important optimization decisions (locality, parallelism, vectorization) are specified separately from the algorithm. It's usually impossible to express an algorithm without implicitly or explicitly specifying those things.
This is both a straw man (OP asked for limited help, not omnipotence), and predicting the future by drawing a line from the past.
Functional compilers that outperform hand tuned C++ on many core machines may be possible, but very hard. Just because everyone has previously underestimated the difficulty does not mean it's an idea worthy of derision.
I think it's much more likely that it's perpetually ten years away, until one day it's not (like the current, possibly temporary end to Moore's Law).
Watching Simon Peyton Jones' talk on data parallel Haskell, I'd not make a bet against high performance Haskell's eventual success, especially as core counts continue to climb, and NUMA gets more NU.
We're already there [1] for vectorized code (Haskell vs. Hand written C). Note how they compare naive haskell solutions with their vector library vs. heavily optimized C code and using finely tuned libraries. And they are competitive, actually beating the finely tuned library in non-toy examples while still using naive haskell.
I'm not going to say it's trivial, but I will definitely claim that beating C is very doable, and will happen in less than ten years, if I have any say in the matter. Obviously this claim should be taken with a grain of salt, but in ten years we'll see who was right :)
Beating C today or beating C as it will be then? If the latter, what do you believe makes functional languages different such that C compilers (with large-budgeted industry teams behind them) won't be able to take advantage of the same techniques?
Two big advantages are referential transparency and memory aliasing. The sort of reordering of loops/memory/whatever like described on the Halide page is just the beginning of the kind of optimizations that are possible. Perhaps static analysis could ameliorate this to some extent, but it will take far more computational power, and will always be subject to the halting problem. There's also current problems with the C standard that could change in a new standard, or maybe optionally ignored in the compiler, so it depends on your definition of "C". Examples of this are struct member ordering being fixed, or lack of tail call optimization (at least guaranteed TCO), and perhaps you might include calling conventions in that.
There's also the huge advantages you can get in programmer productivity. Metaprogramming, better type systems, better (and more) abstractions, automatic memory management, automatic parallelization, there's really tons of room for improvement in so many areas. And a lot of these provide lots of room for optimization, in the sense that they put more of the program semantics into the compiler's hands. Compilers will probably be "stupid" for a long time, but at the very least they are very accurate and very fast, so they can try out many possibilities and measure what works best. Chess is a good analog here--computers are far superior to humans these days, and they got there by just trying tons of permutations of simple algorithms and running lots of tests. Writing compilers turns out to be a similar problem, so moving away from C/C++ can have advantages at multiple levels (so meta!).
It's still in a very nascent stage, but the language I've been working on should eventually be the manifestation of lots of these ideas: https://github.com/zwegner/mutagen Most of the ideas are just in my head at this point, and still rather fuzzy, but there's some specifics in the README about possible future directions.
For my masters thesis I wrote a program that annotated C++ code, ran it, then collected the memory reference patterns and tried to reorder loops by doing image analysis (mainly Hough transforms) on the data.
To be honest it wasn't a very successful approach, so you can probably take this as being a path NOT to try.
I will attempt to find the thesis and update this comment with a link if I can find it ...
As far as I know there are efforts to bring such techniques into C/C++. For example, see GCC Graphite framework - http://gcc.gnu.org/wiki/Graphite .
And meantime, in the real life, if you really need your code to run really really fast (like, if you are doing nanosecond level realtimish staff in finance; or working on real-time computer vision; or anything else that really really needs low level optimizations) if you want to be competitive, you just have to go down to plain C level. And while at it, also have good understanding of your cache/memory/processors/bus architecture, cache interference, costs of system calls, compiler behavior, CPU behavior (microcode level, i.e. cache coherence or memory sync algos) and so on. You can try to not to do it, and attempt to use Haskel or Ocaml, but the cost would be two orders of magnitude. For a real-timish function that you are concerned about, in a relatively well written C/C++ you can have 200ns ± 100ns. The same function in a well written Ocaml will give you 5us ± 200us, and the same in Haskel or Python will give 20us ± 200us (when giving these numbers/example, I assume that the code is written using best possible at the current state of the art data structures and algorithms; all the aforementioned issues are well understood by the developer and the code is written at a greater guru level ;))
I will not be surprised if it beats C as it will be then, by generating C code itself, but C code that no human would write by hand. It has been done before in programming history (not just C, fortran has been beaten as well http://dl.acm.org/citation.cfm?id=200989http://link.springer.com/chapter/10.1007/978-3-642-19014-8_1...http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.150... although the prior art focuses on Lisp I think Haskell and ML like languages are better equipped for this). Imperative code is a lot harder to reason about, and low level code is a lot harder to write if one cares about correctness and performance simultaneously. Specialized functional languages has a history of beating C implementations. It could be faster still if one removes the constraint that one has to generate C code, for example coroutines and proper tail calls become easier to implement. The bottomline is that correctness is easier to achieve with functional, and performance with imperative. So we would need both and they meet in a compiler.
Take the example of Stalin and StalinGrad, they are Lisps. Their compile times are epic, but once done they have a history of generating faster code than C for specific applications (a specific example where it will excel is multidimensional numeric integration where the function to be integrated is passed as an input). The main reason why they would be able to generate faster code is that they are smarter about inlining. The reason they are smarter about inlining is that programmers intent is better preserved when encoded in a higher level language.
Can a programmer not write the same code in C by hand ? Sure they can, but it will take longer and would be more error prone and likely to be costlier to produce, unless one takes the help of these higher level abstractions primitives, but then you aren't really writing in C anymore. Can the C compiler not be equally smart ? possibly, but it will be a lot harder to make a C compiler smart than a functional language compiler smart. Functional languages leave a lot of room for the compiler to do its thing, C while not as bad as Java still over-specifies how exactly something needs to be computed (my way or the highway). Add the fact that when code is written in a higher level, but optimization friendly language one can enjoy the benefits of compiler techniques yet to come. It future-proofs the code to an extent and amortizes the effort that went into writing the compiler.
Now of course one can use C++ template metaprogramming to do much of the inlining that Stalin does, but then again you are essentially using a functional programming paradigm.
EDIT: HN easy on the downvote. You may not agree with stephencanon but there was nothing in his comment that deserves a downvote, seriously ! @stephencanon compensated to the best of my ability.
That particular feature sounds awesome — but there's nothing about it on the language's front page; may be you have a link to an article or blog post about it? Sorry for asking, but my google-fu seems weak today.
You can see it a little bit in the blur example on the front page: the blur algorithm is described in two lines and the optimizations are described separately in the "schedule" below. In this case the schedule specifies that intermediate results should be computed in tiles of a certain size, and the whole thing is both vectorized and parallelized.
Truly impressed by Halide after watching the video. This could really be a game changer for writing e.g. deep-learning related code such as Convolutional Neural Network evaluation and training.
What kind of applications are you using it for? In my experience I've only seen research image processing using it (and even that totally dwarfed by OpenCL / other alternatives)
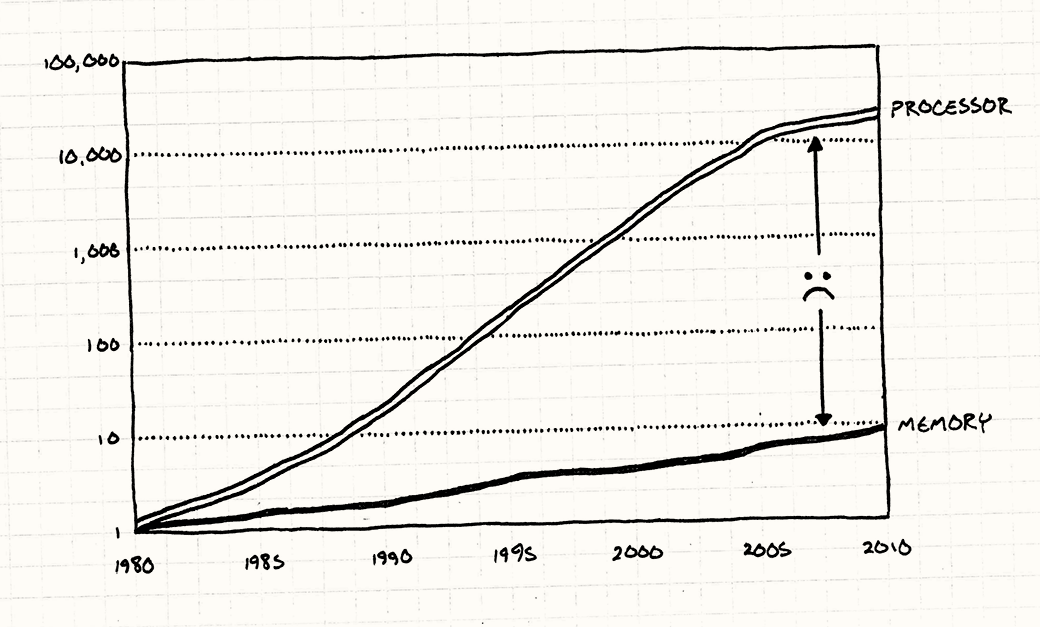
If you are interested in seeing specific data on the effect caching has on memory bandwidth, you might want to check out this paper I wrote back in 2011[1].
Some of my findings:
- Effective bandwidth is approximately 6x greater for data that fits in L1, 4.3x greater if it fits in L2, and 2.9x greater if it fits in L3.
- Contention for shared L3 cache can limit the speedup you get from parallelization. For instance, running two threads for a data set that fits in L3 results in a speedup of only 1.75x, rather than 2x. Four threads on one four-core processor results in a speedup of only 2x vs the single-threaded program.
- It takes relatively few operations for programs to become compute-bound rather than memory bound. If 8 or more "add" operations were performed per data access, we found that the effects of caching disappeared almost completely, and the program's execution was limited by processor rather than the memory bottleneck.
The specific magnitude of these results is machine-dependent, but I would expect the general relationships to hold for other machines with a similar cache hierarchy.
I think they'd differ from the author here that this isn't an optimization to go to when performance starts to suffer, but a design that you have to start using from the beginning, because it's a big change to refactor everything to this style.
There was also a talk on this from Mike Action (Engine Director at Insomniac) at GDC this year. He echoed the same sentiment that cache misses are the main source of performance problems in software. I only partially agree, as network calls are several orders of magnitude slower, and in many services that's actually your bottle neck, not the cache misses.
The best cache-aware programming lesson I ever received was in the CS61C course at Berkeley -- building a cache-blocking algorithm to run a matrix multiplication function using the cache as efficiently as possible. We unrolled loops so that the size of each iteration was exactly the size of one cache block, and saw instantly the increase in FLOpS.
Then we did some OpenMP parallelization. That was cool.
I had a similar project in a programming for performance class at UT Austin. We had access to TACC supercomputers and were tasked with finding the CPU's L1 cache size via trial and error. We were testing it by using matrix multiplication and measuring performance output, and changing the chunk sizes accordingly.
Martin Thompson has a blog and a series of talks on "Mechanical Sympathy" -- being in tune with the machine to extract performance, like a race car driver.
I hope universities start to catch up and build this, along with distributed systems computing and networking, into their core curriculum.
Mix multi-threaded programming with cache effects and there is a whole new world of side effects and un-expected results. There is a side-note in the article about it, but I think that deserve a whole article on it too!
It is interesting that this kind of plays a bit in the favor of functional languages. They are often data centric more than code centric. As in your lay out your data then pass it to your functions as opposed to thinking about the layout of the functionality as different objects that just happen to encapsulate data (so this separates and breaks down the data).
For those on GNU/Linux who want to know about the CPU caches on their machine the "lscpu" gives more detailed cache info than /proc/cpuinfo.
I got curious about how lscpu was determining L1 Data and L1 Instruction caches. So I had a look at the source code of lscpu and found that it was looking in /sys/devices/system/cpu/cpu/cache/ and /sys/devices/system/cpu/cpu/topology/
So this is all cool, and it's incredibly nifty to have the hardware insight while writing software. But these optimizations (loop tiling, loop fusion, etc) could (and, to my knowledge, ARE) part of basic gcc and java compilers. Why are they not more commonly used? Why do we have to specifically provide a flag to say "Hey btw I almost forgot, make my program 50 times faster."
I'm slightly in the dark as to why loop optimizations are not part of the default compile process.
Optimization takes serious amounts of time - it's generally a combinatorial problem. If you are not building for production release, do you want to sit for 5 minutes (or 5 hours for a big system) while the compiler cranks away optimizing code that you are just going to rebuild in 20 minutes anyway? Plus, it just doesn't matter for a lot of production code. Finally, if the code is not in a hot path, it really doesn't matter if it is optimized or not. If you make a block of code 10x faster, but some other loop costs you 50% of the performance time, well, you really gained almost nothing. So, heavy optimization tends to be something that you turn on selectively and judiciously.
You'd be surprised. Gcc usually won't do loop interchange, which makes a huge difference for many programs, and you have to treat it just right for vectorization to work. It tries, but it's easy to write code it won't optimize.
Alignment is another key the author forgot to mention. Cache aligning data is seriously important, even if it means padding stuff like crazy. Caches are pretty big, but having to load two different cache lines and do some bit trickery is a real killer.
Also, if you really want performance, go parallel. Cilk is amazing and there are forks of both gcc and clang with cilk. Cilk is seriously awesome.
Of course that doesn't apply to games anymore but to high performance computing. Systems for gaming vary too much for that to be of any importance. Maybe if you are doing it for the consoles, but then you have to optimize each individually.
There are some interesting implications on databases in terms of column-stores vs row-stores due to CPU caching. Besides the I/O improvements, column-stores benefit greatly from better CPU usage because the data is iterated over by type (column by column), so the same operators stay in the cache. This allows data to be pipelined in to the CPU and processed very quickly relative to traditional row-stores. It can even be efficient to operate on compressed data [1] if the relevant decoding data can be kept in the cache.
In case you missed it, there was a relevant article last week about how B-Trees benefit by reducing the number of cache requests.
I was curious about this as I have never done any such testing, so I wrote a simple c program.
The object was a struct with a size of a typical game object( 100B ),
then I trashed the memory by doing a lot of malloc/free using the size of the object. The two tests were one with an array of objects( contiguous array ) and the other an array of pointers to objects which were allocated separately. Then I iterated over the object doing some very simple operation( just enough to access it, and identical for each object ) and timed this. And of course I trashed the memory some more for each time.
The time taken ratio is:
array of objects : array of pointers to objects
1 : 1.189
The second test is identical except I made some extra effort to make sure that every object in array of pointers was not adjacent to any previous one in memory:
array of objects : array of pointers to objects
1 : 2.483
The difference got much smaller once the operation on each object became more time consuming.
There is also the topic of Cache Oblivious data structures. Sadly, I'm still trying to figure that one out but it looks like it could help. Both with the memory and cache access time disparities and it is claimed that also with the memory to disk disparities.
If someone knows of an easier to digest explanation than the proof-laden academic articles I'd appreciate a pointer :-)
can you give a hint? i think i understand the article (well, i haven't read it, but i sometimes need to tailor code to work better with the cache on a cpu), but i don't know what you're referring to.
{kind=link}