Why is debugging IAM policies and auth issues such complete dogshit on AWS? Seriously, if you want to be a competitor, focus on this.
I've wasted hours trying to work out why I get an unauthorised error, and the official docs say to manually pick your way through the 8 or so different policies that might apply (SCPs, IAM, resource policies, etc). Yeah right.
When you eventually find the page showing how to use Athena with Cloudtrail, you discover half the requests are inexplicably missing. And even though error messages include a request ID, you can't easily query for them, if it's even possible. Maybe it is and I just haven't discovered the right athena incantation. They should make it easy to just query by request ID and get clear messages telling you what policy denied the request.
It's a total train wreck from start to finish. I guess by keeping such a shitshow they sell more support contracts though.
A cynic in me is happy about this state of affairs - the companies who happily joined the AWS bandwagon have to pay the price (including my salary). For my projects I almost always choose something else that offers better value, except in very rare cases when it makes sense.
A decade ago or so AWS was marketed as - to simplify - "fire all your sysadmins because we manage the systems for you" to the current state where good AWS DevOps engineers are expensive and not so easy to find and you pay through the nose if you really follow AWS recommendations, especially for larger setups.
CTOs bought the "fire all your sysadmins" literally, and now we have a 20% overhead on all app devs who are supposed to learn all this stuff.
It's crazy to me. It's literally the opposite of every management training / book about focussing on highest value work / where you add value / where you provide expertise.
20%? Seems like at least half of all the work has to do with infrastructure plumbing, now that people who are supposed to write product code are expected to be Cloud prodigies.
When I was at a company that went all in on AWS. I went from 100% of time working on product, to easy 75% of time working on AWS. Even though we had teams who just set up infra on aws for us to use and it was supposed to be "so easy". There was far more time setting up AWS infra than writing code.
Yes, and management discounts that .. if you make me, a product expert, working on application software.. deal with this stuff, I am going to do the worst, most rapid, half-assed, security and everything else be damned job.
I have clients, product, scrum masters, tech leads, and others breathing down my neck on feature delivery, and you're asking me to figure this alphabet soup out, lol.. don't expect happy results dudes.
I've been a domain expert in a field for 20 years, what value do I bring to the client in dealing with this alphabet soup of AWS networking/security? Either it works and client gets what they want, or it doesn't and they don't.
This stuff is a full time job and should be respected as such. If you think you can push it all down on app dev, you are going to have unhappy results.
would you mind elaborating on the nat gateway part? are you insinuating that nat gateway as mean to provide oneway internet access for instances in private subnets are misguided or suboptimal?
> Why is debugging IAM policies and auth issues such complete dogshit on AWS? Seriously, if you want to be a competitor, focus on this.
System managed identities + AAD is an absolute joy in my experience on Azure. I can grant a function app access to a SQL database by simply using the literal name of the function app (qualified by the object's identifier if aliased). No passwords, certificates, etc. involved anymore. It literally just works.
Combine their auth package with things like application insights, and you are not really ever stuck thinking "WTF happened", assuming you have enough awareness to look at those logs.
> I guess by keeping such a shitshow they sell more support contracts though.
This is also a problem with Azure. You really have to know where all of the mines are located before you start walking through their field or you will wind up in a similar state of contorted frustration. I'd argue that Microsoft leaves substantially better hints regarding where mines might be, but they still conveniently leave out enough hints such that only a wizard with 2 decades of experience can pierce the final veil of bullshit and avoid a 5-10x multiple on cost & complexity.
Azure SQL Database, Managed Instance, and SQL 2022 in a VM all support AAD authentication.
Okay.
SQL 2022 supports only user accounts and not managed identities.
SQL Managed Instance requires an additional global AAD permission button to be pressed post-deployment or it won’t work. This can’t be templated.
The first two have AAD permissions controlled via their template (ARM API) — but only exactly one full admin group. All other permissions must be assigned via T-SQL. Again, can’t be templated via ARM. (Microsoft has better data plane RBAC for random open source products than their own flagship database!)
User access audit logs are easily collected for Azure SQL Database, needs manual T-SQL for SQL MI and is missing in action for SQL Server.
This is just SQL, which now at least supports user-assigned managed identities… if you include the latest SQL client which has a breaking namespace change and hence won’t work with third-party code. It also drags in 500 MB of dependencies.
Lightweight functions, you were saying? Hmmm…
Anyway, I got fed up with the whole thing when I tried hooking up a Storage Account in the same way and discovered that it didn’t support UMSI in connection strings — you need two code paths for dev-time and runtime!
Up until recently the whole thing was an unstable mess. Authentication would take 5 seconds in some scenarios and then wouldn’t cache the tickets properly.
It turns out that every Azure team is implementing the whole thing separately! It’s not at all like traditional AD where the platform provides the authentication functions in a uniform way and apps can just pick up the ambient tokens.
No, in this shiny new world every service does RBAC differently, connection strings differently, auditing differently, caching, config, and on and on.
All of this within 100% Microsoft products and services.
I am not sure I understand. The "toys" you describe are all we need to get the job done. Azure SQL Hyperscale, Azure Functions C#/v4, AAD, another region for DR (SQL geo replica + Function App x2) and that's about it... Why do we want to make this hard?
If you want to try to force the square peg through the round hole, I get it. It's going to be a clusterfuck as you describe. But, I decided we were going to get completely trashed on the Microsoft kool-aid so we don't have to worry about 3rd party clients and other non-happy-path integrations. I click 1 big dumb button in my Visual Studio client and some time later my app is running on a live URL completely managed by Microsoft. This is a pretty good life. I don't have patience for things like I used to. Leadership & investors are not giving me much to work with these days.
> square peg through the round hole ... Why do we want to make this hard?
I work in a job where I don't get to make product decisions, I just have to "make it work" on the cloud.
Despite this, the only applications I've worked on in the last three years have all been ASP.NET web apps with SQL databases. Even with this pretty vanilla combo, I found hundreds of bugs or interoperability issues in Azure. These aren't esoteric things, they're not round pegs and square holes. These are Microsoft-shaped pegs that ought to fit into Microsoft-shaped holes.
Things get messy the instant you step off the "tech demo MVP" happy path.
Like I said: Third-party code that talks to SQL, Storage Accounts, or SQL databases other than the one of their two Platform-as-a-Service offerings!
Even if you stick to just functions and Azure SQL Databases, there are still limitations and issues.
Templating is painful or impossible. Data-plane RBAC is missing in action. Etc...
If you're a solo developer working a tiny app deployed with click-ops to a single region, then I suppose it is "fine".
Unfortunately with Azure, while authentication may be more obvious, 0x80003007 ERR_UNKNOWN type things aren't.
Also, what's up with the way almost every any change in Azure takes some random period, sometimes hours, to take effect and there's not necessarily any indication that anything is happening.
> I can grant a function app access to a SQL database by simply using the literal name of the function app (qualified by the object's identifier if aliased). No passwords, certificates, etc. involved anymore. It literally just works
I can't comment on the general correctness of your comparison (never having used Azure), but this particular one is flawed, since the same is true in CDK. That said, there's enough arcane weirdness in AWS' configuration requirements that I suspect your point is _broadly_ correct.
Pretty much everything in AWS APIs is a trainwreck. They mindless wrap objects other objects, for seemingly no reason. The customer bears the burden of learning and implementing the extra logic for complex data structures. It's incredibly annoying. They need to pair up UX designers with engineers, but they don't.
FWIW, more debugging information in an IAM failure is another round of information available to me as an attacker. If such a service existed available to the customer this also becomes potentially available to an attacker. In fact, it may wind up violating a few companies’ security and compliance policies.
However, I think that customers should have the option once they sign some stuff acknowledging that they may be really, really screwed similar to Bad Things done as a root user in AWS.
Given the distributed nature of so many requests in AWS I’d imagine that a GraphQL-like setup would be conceptually compatible with such a system. It’s not terribly far from tracing systems like OTEL
For some APIs they return encrypted payloads with actually useful debugging info in, but there seem to be plenty where you just end up in a black hole of "computer says no"
Cloudtrail writes to s3 at intervals, which means it make take a few minutes for the log entry related to your request ID to show.
I've found Athena doesn't appear to search through all log entries (possible user error on my part); I've been downloading the cloudtrail logs directly from S3 and grepping through the logs directly to find the relevant entries to figure out the permissions needed.
If you need to decode an encrypted error message, use `aws sts decode-authorization-message --encoded-message $MESSAGE`. It'll return a JSON string. I typically use `aws --profile limbledevadmin sts decode-authorization-message --output text --encoded-message $MSG | jq .context.action` to extract the needed permission.
Those request IDs can be used if you escalate to AWS support, they can point you in the right direction. It’s generally not a fast process, but it’s something.
And this is why I hate having to deal with AWS. Learning this stuff isn't technical knowledge, it's product knowledge.
I read the TCP/IP illustrated series cover to cover and learned that stuff cold, and this was useful knowledge to me for decades.
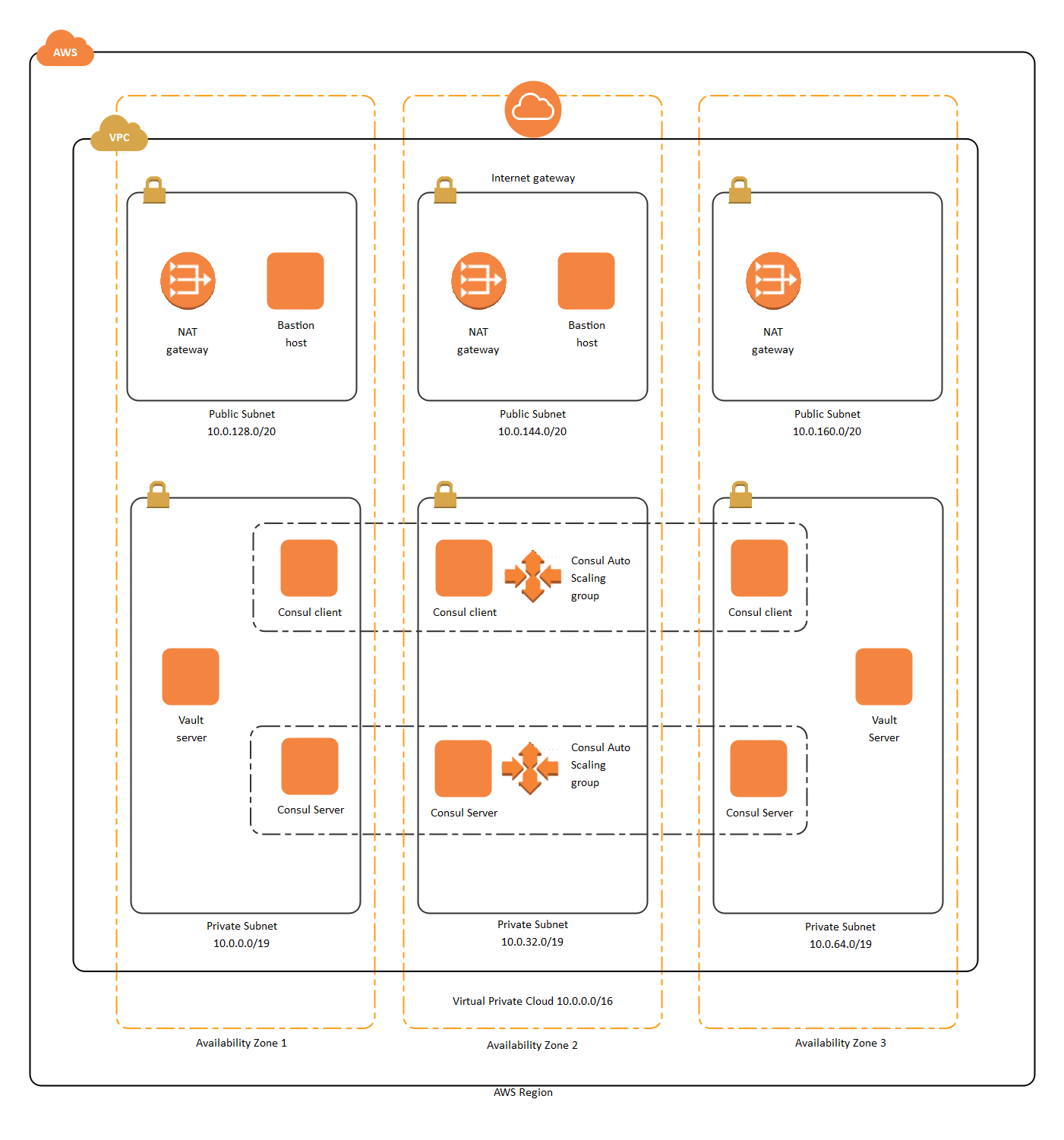
However I always find myself resisting learning this AWS stuff, which is just as complex in its own way too. This diagram makes me feel that if the goal was to simplify things, then I'm not sure how successful they were at that.
> if the goal was to simplify things, then I'm not sure how successful they were at that.
Maybe if they have other goals that are tradeoffs vs. simplicity, then it's more understandable?
What if another goal is allowing enterprise customers to recreate a virtual enterprise network? Or a virtual data center network? Those are much more complex than a client TCP stack.
The defaults are simple for simple uses. And yes, for those complex cases, you'd need AWS specific product knowledge, but most of the underlying concepts are shared in common with other clouds and on prem networks. Like learning your Nth programming language.
AWS used to be not only sane but elegant: every instance had an entirely-arbitrary internal/private IP address, some could optionally have a second public address, and which instances (including external IP addresses) could talk to which other instances was entirely and solely defined by security groups (as well as, of course, any OS-level firewalls that you'd generally disable), which were pretty much just flexible and reusable firewall rules where the concept of a "security group" replaced entirely the concept of a "subnet", which became an obsolete legacy concept.
They needed to support multiple adapters per instance, which they later added (maybe with a separate security group per adapter, which they might support now but I don't know off-hand); and they also needed hierarchical security group inheritance (the same way traditional subnets can nest into each other), which they didn't add but I guess you can now simulate them (though this sucks and I think is part of the downfall of the elegant stack) using multiple non-hierarchical security groups (which was not supported originally: security groups were permanently fixed in a one-to-one relationship with an instance).
This original elegant cloud-first model of instances and groups made network engineering pleasant for once... even fun! I remember thinking how great it was that all of my arcane physical networking and routing knowledge might soon be obsolete: that I could now think in terms of the abstractions of instances and how they talk to each other, drawing abstract circles around them without having to think about limited address spaces, and that they would assuredly fix the only two shortcomings of the original model...
...but then the network engineers showed up in force and ruined it all. There is simply no good reason for all of this VPC IP-address subnet focused insanity once you go cloud: they are just re-instating all of the frustrating limitations that come up when doing real world network engineering, presumably because they weren't willing to throw away their knowledge and realize all of that stuff is obsolete.
Like, seriously: we want to be able to replicate some enterprise network? That's madness, and it makes it all worse for everyone that this is even a supported goal. This is all virtualized networking: we don't need to be thinking in terms of subnets and gateways, we don't need to be manually configuring our egress... if you have a ton of hubs and routers and have to run cable all over the place, it makes sense, but this is the cloud!
And so now we all actually had to brush off all of that networking knowledge I was happy to give up as Amazon deprecated and fully removed "EC2 Classic" and have forced us all into this VPC insanity; and maybe if you never really tried to grok how AWS worked 15 years ago when it wasn't pretending to be a pile of legacy networking equipment you just shrug and accept that this somehow is all necessary, but it really isn't.
>...but then the network engineers showed up in force and ruined it all.
I've never met a single network engineer who had anything good to say about any of the cloud networking environments. I have met a bunch of network engineers who were told by management "go recreate our data center network in the 'cloud'. We're moving everything there over the next 18 months. No, we aren't going to re-factor any of our apps in the process."
That's why all these kludges exist in AWS and other public cloud environments.
On the flip side, the unnecessary AWS complexity is a great make work program for developers. You now need an army of developers (and AWS "architects") to make a truly complex behemoth that fully replicates the insanity of a 50 year old enterprise system. A system of such complexity no single person can understand it all, all changes take days to weeks to make, and its behind black boxes everywhere. That's progress.
They recently launched https://aws.amazon.com/vpc/lattice/ which basically feels like EC2-classic emulation layer on top of VPC. which is a funny full circle but it works.
What they need to make are standards. Then it becomes technical knowledge for civilisation and not just single-company product knowledge. It would be great if cloud companies made cloud networking standards. I mean big competitors used to collaborate and make standards before but all that has petered out over the last couple of decades.
I thought the other goal was to make it easy to get in but very difficult to leave so you are practically forced to keep using their services. Customer capture.
> Learning this stuff isn't technical knowledge, it's product knowledge.
Not really, and mostly I think you're looking at it through the lens of a different field. TCP/IP is going to be the knowledge useful to your network programmer. One of my college courses was networking: we covered networks, subnets, route tables, routing protocols (such as RIP, OSPF, BGP), NAT, etc. We did all this on actual hardware, and the course was heavily sponsored by Cisco (so much that by the end of the semester, you were CCNA certified). In that vein, yes, I picked up a lot of "product knowledge" on how Cisco products behave, 95% of which I've probably forgotten. But that was to give us hands on experience, and the underlying concepts translate well into Azure, AWS, or GCP. These cloud VPCs are mostly virtual analogs to the real deal, much like how VMs are analogs to a real machine. If you understand a real machine, a VM (and associated resources like cloud disks or NICs) aren't going to be that mysterious.
In particular, NAT confuses the living daylights out of people. But, that's almost to be expected. More down to earth, many eng struggle with CIDR notation, or even — but this gets back to your stuff — TCP (e.g., they think that a send() will send the passed buffer as a unit, or that a recv() will always receive a full "message" of some sort; most eng struggle to understand the difference between connection timeouts and peer resets, and when one can happen and the other cannot).
The dark side of this coin is that I really wish I didn't need a lot of this knowledge; it is a lot of junk. IPv6 makes networks so big that a lot of network planning and subnet sizing and "will it have enough room to grow but also not exhaust the range?" just goes away. NAT can die in a cold icy hell. If I could never see another VPN in my life, that'd be cool. (Just use TLS, for the love of everything dear.) I could also do away with cloud firewalls using IP addresses as a form of auth, and delivering misleading errors when triggered. (Azure is horrid at this.)
(I do hope that most products are technically simple enough to not need much of this knowledge. If you do TLS, you shouldn't need to be doing VPCs, non-default route tables, network peering, etc. I'm in a field where we integrate with a lot of people who have no desire for technical simplicity.)
I share this perspective. Most boxes in this diagram are AWS names for a thing existing in normal datacenter or TCP/IP networking. I am an old schooler who personally never worked a lot with AWS, but I think this is pretty clean.
I think it's a boiling frog scenario. AWS's goal is marketshare, not simplicity. Like many professional software products, it started simple by necessity and then grew more complex over time. In AWS's case it ballooned pretty quickly due to the compelling nature of fully-managed on-demand infra services and the huge amount of resources Amazon poured into it.
The value add for not having to directly interact with hardware is still pretty high, but you definitely pay a price (in addition to the sticker price) for it in terms non-transferable vendor-specific knowledge.
Yep, it would be nice if they had used standard terminology. Example: a "virtual router" that you could configure (with internet, NAT, connections to other VPCs, firewall rules, etc.) Instead, you have all sorts of one offs: "internet gateways", "NAT gateways", "egress only internet gateways", "transit gateways." We're going to wind up with a whole generation of engineers that only understand "cloud" and not how things actually work.
My suspicion is that they have distinct names/skus because (a) they're billed differently (b) they represent different security choices. If I grant a developer's account the ability to create "virtual router" entities, that means said developer can do all kinds of things I may not approve of. If I grant them only the ability to create "Internet gateway" entities, I know exactly what I'm getting into and (more or less) what I should expect the bill to be for that
I do agree with you that having a separate "egress-only Internet gateway" for IPv6 is dumb and confusing. I'm sure there's some number of pizzas which explains this Conway's Law instance
Undifferentiated heavy lifting. Companies don't have to train their engineers and find talent that requires deep knowledge of tcp/ip and hardware routers and clean up the mess when they leave and maintain them. Offload all of the "undifferentiated" components to AWS and you focus on what you are good at, your business.
The big 3 work very hard to make sure you’re learning their product so you can advocate for it (because it’s what you now live and breathe) and sell it to others.
Who needs a marketing team when you’re making everyone a “tech evangelist” for your product.
If they offered just normal global addressing + firewalling, most of this complexity would just go away.
We easily forget what the internet at the IP level is about and what problems its end-to-end architecture solves.
AWS instructed "Well-Architected (TM)" networking is really just profitable cargo cult thinking leading to complexity, mazes of 10.x networks all alike peppered by address conflicts, kludgey proxies etc when you try to get them to talk to each other, less actual security (complexity is the enemy of security), and vendor lock-in.
It's also nuts to me that we take senior engineers who have domain expertise in solving business problems, and thanks to "the cloud", I'm supposed to become DevOps/NetworkOps/SecOps and terraform my way to the perfect networking/firewall/cybersecurity/etc solution for my application.
It's not like the old sysadmins made 1/2 or 1/4 of my comp, and usually 1 of them managed enough hardware to cover 100 devs. So we are talking what, a 0.5% overhead for the rest of us to avoid mission creep & brain damage of this stuff?
Literal "Death of Expertise" here with AWS yet again.
Can't agree more, if decision makers would more often ask themselves 'should we do it' instead of 'how we can do it'. But engineers gotta engineer and managers gotta manage or they are obsolete.
But then we would have fraction of projects and work and just evolved systems created decade or two ago, with much lower IT costs. A total nightmare I say.
Isn't this sort of what Amazon Lightsail is? (Haven't actually used it, but am under the impression it abstracts away networking config).
I'll probably get downvoted, but isn't global addressing + firewalling basically available by creating a VPC with only public subnets, and using security groups as your firewall? (Best practice is public/private subnets with NAT gateways, but it's probably not impossible to rely only on security groups)
> Isn't this sort of what Amazon Lightsail is? (Haven't actually used it, but am under the impression it abstracts away networking config).
Yes. Many services abstract networking. App Runner, for example, even gives you a public URL with HTTPs. Lambda also can do that nowadays. Most managed services just expose endpoints.
> I'll probably get downvoted, but isn't global addressing + firewalling basically available by creating a VPC with only public subnets, and using security groups as your firewall? (Best practice is public/private subnets with NAT gateways, but it's probably not impossible to rely only on security groups)
I will also disagree with what others are saying. You can keep things simple in AWS if your use case is simple and never care about 99% of what's on the AWS VPC dashboard.
If your use case is complex (you need to connect several internal private apps, expose private things behind a single IP / FQDN, do load balancing, use private DNS, connect with other clouds and on-premises, segregate, monitor and authenticate traffic...) then using physical appliances would likely require more hard work and expertise.
A fun exercise to folks complaining about AWS complexity: go to Fortinet's web site and try to find out which appliances you should use to secure a small company (~ 100 employees, couple of public internet facing services, couple of internal apps), how much it costs and how can you buy it.
Mellanox switch is like $10k a pop. You install Linux on it (sonic) and configure firewall/vip/etc and you’re done. You can pay consultants to do all that once then save on aws cost for next 3 years.
37signals did basically this with same number of staff you can read about it on their blog. It’s not rocket science
Well if it’s that simple and 37 signals did it, then obviously everyone should!
It’s not like your description is ridiculously reductive, or like 37 signals/dhh have a history of attention seeking behavior that might drive them to make technical decisions on the basis of PR value. Never!
Not as reductive as your typical Certified Cloud “Architect’s” pitch ;)
This is not a question of why they did it (although they pretty clearly expand on it in those posts and everyone who didn’t flunk middleschool math can do the same with their setup) but question of can you do it. And the answer is pretty clearly - yes. But ofc you won’t, and not because of technical reasons either.
Either Lightsail, or just the default VPC that all AWS accounts come with.
If you think your use case needs private/public subnets, NAT, complex routing tables, etc. you can still add that to the default VPC later.
A few years ago, when what we now call EC2 classic was a thing, there were no sophisticated networking options at all. I assume VPC and its services were introduced because customers asked for something that feels like traditional datacenter networking.
This stuff is obviously so hard to use that even the experts don't know wtf they are doing.
At a prev shop, they undersized the VPC had sporadic failures of burst compute like spot instances that got spun up by other AWS services (Batch) to work through job queues. Neither the cloud architect or CloudOps lead could resolve this for months, or even temporarily prevent the breaches, until a big VPC resize / reshuffle / migration over a weekend. Probably $1M/year TC between these two guys. Incredible stuff.
Felt like on-prem kind of stuff that I was reliably told the cloud solved.
It may be possible (though there are practical impediments as well, such as the poor IPv6 support), but the expectations and culture in the AWS world are so ingrained that you'll be looked at funny and constantly have to defend the "unorthodox" choices.
There is more to it; many companies have security organizations that insist on bringing the same security concepts as they have on prem to the cloud; many regulators do as well, so this requires a lot of what we see in terms of the unnecessary complexity in the cloud in terms of networking.
10.x subnets conflicting around is kinda the norm outside if the cloud too. I’ve seen that myself while configuring a vpn between two companies, and ultimately we had to do some kind of nat trickery to get the thing going.
The solution would be ipv6 and ula prefixes, but that’s another can of worms. I’d love to see it implemeted, but stay assured it’ll come with its own set of issues, complexities and difficulties.
Well, then thank goodness IPv6 also still supports firewall rules. It is a whole different discussion when one wishes to conditionally allow Office Building 1 of a company to connect to Office Building 2 of that same company by updating some ingress rules versus the "well, site-to-site VPN sometimes works and stays up the whole workday"
And that’s part of the problem IME from the customer side. Many of the largest pockets come from those with the worst technical debt and cultural issues of past mistakes and trends all done precisely while trying to avoid said mistakes. While part of the point of many different vendors is for resiliency as an enterprise much of the complexity is frankly various forms of proprietary vendor lock-in tactics trying to entrench themselves in some way to these high value, low churn accounts which starts to become more of a politicking or spear phishing exercise to the C-suite than anything about the solution itself. Essentially, every other bad technology decision in hindsight comes from many of the underlying problems that cause people to develop rather poorly thought out, shallow opinions unrelated to technology - confirmation bias.
As such, sales to me is one of the ultimately lucrative forms of social engineering attacks that oftentimes leaves the victim feeling like they got something when they really are just paying to feel like someone’s solving something for them.
it's basically embrace (use accepted concepts like ip, network interface, subnet etc), then extend (make it easier to work with those concepts at least for simple use cases), then extinguish (network services only look like the real thing).
I think the mindmap drawn can be simplified further down into a couple of networking concepts, then most of the relationships and arrows go away, and the AWS concepts can be mapped to other clouds, and even your own home network.
https://news.ycombinator.com/item?id=18925350 is an excellent visualization of the basics. Start with what a network is, what’s inside and what’s outside, and the mental model becomes way easier. Then the AWS features make a lot of sense even w/o all the details.
Excellent share, thank you. In comparison, the OPs diagram offers a 'plan-it-yourself' type view of the provided AWS services, and as a mindmapping artefact, has no doubt aided the author to come to grips with the complexities of AWS.
And the result is something that summarises a complex system clearly and succinctly. Thanks for sharing OP, I'll be consulting this the next time I'm wading through the AWS forest.
Agreed, my network diagrams for AWS basically has nested squares. For example, a subnet inside an availability zone square, and that is inside a VPC, and that square is inside a region. Kind of like this but looks nicer: https://images.edrawsoft.com/articles/aws-diagram-examples/e...
I remember the heady early days of the cloud when AWS networking was simple.
Even then, I saw this coming, of course. There's no way to "be everything for everybody" without also duplicating the insanity that is legacy IPv4 data centre networking.
Just recently, I wanted to do something conceptually simple in Azure: NOT have the storage account with our database backups "on the Internet" for the world to poke and prod at will.
So simple! Just turn on the firewall... and oh boy...
You can whitelist only subnets. Individual subnets. One. At. A. Time. Not virtual networks. Definitely not "all" of your virtual networks, which works elsewhere perfectly fine.
Okay, fine, there's a Private Endpoint feature as well. Sure, it kills performance and costs extra, but there's nothing wrong with having this cost money, right? After all, flipping the address in some config of a software-defined-network (SDN) from "public" to "private" is hard work and the gremlins in the cloud need to be compensated.
Then, err... uh-oh. It doesn't actually work! You need to override DNS to make your clients discover it. So you plug it into your AD domain. Now your PaaS services can't access it.
Okay fine, you create a private DNS zone (which costs more money), link it to a hub network, link a DNS Resolver service to it (which costs more money), then set up a bazillion rules so that your AD domain still works, and then...
... where was I again? I started this a week ago.
Oh yeah, I just wanted to make sure Russian hackers can't access our backups if a storage key leaks.
Maybe next week I can update the subscription templates to re-deploy all the virtual networks with the updated DNS settings.
Not idempotent, you say? Maybe next year they'll have a preview?
Never mind, I hope the Russians won't get mad at us in the next few months...
You setup VNETs with private endpoints and then configure your and the azure DNS to talk together with magic, and you can do what it is you want to do. Then you can use public gateways or front doors for anything facing the public. I’m not a big fan, but it’s not like it wasn’t very complex before. It’s just that now developers are more exposed to the insane mess that is enterprise networking where before it was strictly an ops thing. It’s still mainly an ops thing, which is why I called the DNS setup magic because that’s the part of it I don’t ever touch. Of course you do need to plan ahead, especially if you’re using app services and multiple subscriptions as you can’t share subnets, and also don’t want to run out of IP address space I’d you use app slots.
What I don’t personally get with Azure is why the “default” settings for enterprise isn’t that everything is not on the internet. Then when you need to do something on the internet, you’d need to open up. You’re likely going to need to set up a bunch of things like load balancer a and what not anyway, so the process of putting something on the internet is complicated to begin with, but everything should just be off the internet by default. At least as some Enterprise setting or whatever.
But I guess part of it is that Microsoft sells Azure certifications and need it to be hard. But why would you want to worry about all this complexity in 2023? At least as the default. It’s fine that it’s very customisable.
> What I don’t personally get with Azure is why the “default” settings for enterprise isn’t that everything is not on the internet. Then when you need to do something on the internet, you’d need to open up.
Because every major cloud provider made the mistake of using IPv4 networking for backwards compatibility with their customer's software from the 1990s.[1]
What they should have done is used IPv6 by default, and provided each customer subscription/account with a /56 in each region sharing a common prefix, e.g.: /48.
All of the private networking complexity just evaporates and turns into trivial firewall rules.
The "allow our vnets only" rule becomes a single /48 subnet allow rule. Want to trust a foreign tenant? Add their single /48 prefix and done! No NAT!
Service Endpoints and Private Endpoints are required only because IPv6 RFC1918 private ranges are too small, and hence overlap between customers. Remove the overlap and you remove the need for any kind of tunnelling or SDN magic.
No more split DNS either: the AAAA records are always the same for every name, whether "inside" or "outside" the network. At most, you might need "private records" that resolve only if the request query comes from the customer's /48 prefix.
And on and on...
IPv4 ought to have been an optional compatibility add-on, a side show to secure-by-default IPv6.
[1] Sadly, there's still software being written today that doesn't work with IPv6.
This is very cool. I feel like the Google Cloud documentation does a relatively good job introducing all such complexity as you need it, but I've never seen such a complete overview for it.
(I did have to go through some effort to view the image. On the page it's too small and it's not clickable, then opening it in a new tab does some imgur-like bullshit where you don't get the image but a useless page where it is still small. I had to download the image to view it.)
This is amazing. Thanks. This also highlights how powerful mind maps / diagrams are when learning cloud products (or other concepts). I used them a lot when studying for my AWS certs and it's amazing how better my mind started understanding interlinked services when presented in a map vs a series of pages, even though I was writing extensive notes. Ofc, YMMV we all learn differently.
I don't understand all of the hate in this thread. Most of the networking systems provided by AWS are as-needed. It may not be elegant, but it gets the job done. Plus a lot of the AWS-specific components map directly to real networking concepts: AZ: cage; VPC: VLAN; PL: cross-account p2p VPN (more or less). Most everything else are normal networking constructs that you would see in a typical large-scale environment.
The company I work for has a fairly complex global network, connected at many of our PoPs to AWS via DX. We utilize all of what you see in this diagram and each component serves a well-defined purpose.
If this diagram looks overly complex to you, it's likely because you either aren't utilizing all of these, or at least not for their intended purpose, or you aren't a network engineer.
This seems so crazily complex! I know only GCP of the three large Cloud vendors, where networking sure isn’t trivial, but still somewhat straightforward and consistent.
Can someone with more multi-Cloud experience chime in and comment on how the big three compare in terms of it being easy or complex to set up internal and external communication?
I've never sat down to do the mapping, but I'm pretty sure almost all the networking concepts and modules in AWS have a more or less direct counterpart in GCP.
Which is not surprising, because most of them also have a direct counterpart in networking standards themselves. They're both essentially just views into the world of software-defined networking.
I honestly don't know how anyone can use AWS properly without some kind of IAC. For me its terraform and I swear AWS will update one small thing and we end up chasing down the most frustrating issues in the infrastructure.
Its made all that much worse how awful their documentation is on most of their services too.
- Flat! Yes, you shared with other AWS customers. Was great to make sure security was turned on (you could watch folks scanning internally at least that's my memory). This made it dirt simple, anything could connect with anything, even cross account.
- EC2 instances were the key items in the flat network (they switched to things like interfaces now which add lots of possible complexity - diagram is missing this).
- One private one public IP address (if desired). Simples.
The whole security story with all the layered possible permissions is crazy now. And the org->account model is clunky with a root account login. I think GCP get's this part better with its project model FWIW. That said, I don't discount what AWS provides.
your diagram is actually insanely useful. they churn out a lot of products but as a user - things are very broken and documentation cannot keep up with it
There is a major flaw in placement of the EC2 instance in this diagram.
Each EC2 instance has 1 or more Network Interfaces, where each Network Interface resides in 1 subnet and can have multiple public and private IP addresses. The diagram currently suggests that an EC2 instance is located in a single subnet — it’s not. Each Network Interface connected to an EC2 instance is only required to be in the same Availability Zone where the instance was launched.
It's like a layer on some of these concepts, but also its own thing that could sit alongside. You can connect AWS and non-AWS things into a network and segment them and define where traffic can flow from/to.
It already went way too far and consider, the outcome will impact all of us. Now we have to ask an Artifical Intelligence to simplify the complexity of getting a footstep in a Cloud Hosting Platform like Google, Amazon or Microsoft. I don't know if this is desireable.
It’s interesting to see how they are piling up complexity as the time passes. Sad to discover new features varnished by marketing terms that on the technical side attempt to fix the problems arised from previous solutions and narrow and struggle the ways to use them.
All these comments plus the new frameworks coming out like SST just go to show most people want a simpler interface to AWS services. I wonder if AWS will provide this themselves or if we’ll always need 3rd parties to do so.
AWS copilot has been very useful for me. It's their cli that tries to simplify integration (and give useful defaults) when you are setting up these services.
I recommend it for anyone who is starting getting into AWS.
The cloud is a big sham. It's a lot more expensive than real hardware, without the control, and with the requirement to go through a maze if inane virtual layers.
There is no need to exaggerate. "The cloud" (I assume you mean the so-called "public cloud") definitely has its place and use cases.
On the other hand, there are people and companies who fell victim of marketing and groupthink to the point where they flat dismiss any solution that is not based on the public cloud, no matter if it makes sense or not. I guess they should pay the price, that's it.
Nice diagram putting it all together. The proliferation of networking features in VPC over the years has been significant and at times confusing, and I work on VPC ;-)
Incidental, but when did this start that some websites when clicking the link for "open image in new tab" (https://miparnisariblog.files.wordpress.com/2023/03/aws-netw...) actually return a new html page showing some useless bullshit around the image, so that I have to download it to actually view it large? This is super annoying. Breaking the default behavior of the browser on purpose is just user-hostile behavior.
lol. This really is the issue. AWS certifications are great way to know how services can be over engineered. Adding seemingly complex solutions to "prove" technical worthiness is an Amazonian thing
It may be useful (perhaps even necessary) if you have to be on AWS. But it is a systemic problem however. Lot of these services have "need to launch something" sticker attached - so AWS keeps adding layers over layers and end up with something very few people understand. First comment is spot on (networking tends to be a cargo cult)! Certifications tend to be in architect's space (talkers) while the real coders (builders) who build systems hardly want to know these things.
P.S - FYI I am nX AWS certified myself, so part of the clan :)
{kind=link}
{kind=link}
I've wasted hours trying to work out why I get an unauthorised error, and the official docs say to manually pick your way through the 8 or so different policies that might apply (SCPs, IAM, resource policies, etc). Yeah right.
When you eventually find the page showing how to use Athena with Cloudtrail, you discover half the requests are inexplicably missing. And even though error messages include a request ID, you can't easily query for them, if it's even possible. Maybe it is and I just haven't discovered the right athena incantation. They should make it easy to just query by request ID and get clear messages telling you what policy denied the request.
It's a total train wreck from start to finish. I guess by keeping such a shitshow they sell more support contracts though.